
🔸Intro🔸
오늘은 스택과 큐에 관한 기본적인 이론을 알아보려고 합니다.
BFS(너비 우선 탐색)과 DFS(깊이 우선 탐색)을 공부하던 도중, '왜 DFS가 메모리 사용량이 적고 BFS는 메모리 사용량이 많을까?'라는 의문이 생겼습니다. DFS는 Stack기반 구현이고, BFS는 Queue기반 구현이기 때문에 이것에 정답이 있지 않을까 생각이 들어, Stack과 Queue에 대한 이론을 다시 한번 정리해보는 시간을 갖게 되었습니다.
자동목차
스택과 큐는 자료구조 중 선형 자료구조로 연속적으로 데이터가 나열되는 형태를 가집니다.
📌스택
🔸스택의 특징
- 후입선출(LIFO) 구조 - 마지막에 들어간 게 먼저 나옴
- 하나의 입구만 사용(입구=출구)
- 메모리 공간을 효율적으로 활용 가능 (사용한 데이터는 즉시 제거 )
상자에 책을 넣는다고 생각해보자. 상자에 책을 넣으면, 마지막에 넣은 책이 제일 위에 위치하고, 제일 위에 위치한 책부터 먼저 꺼낼 수 있다. 가장 아래에 있는 책(=가장 처음에 넣은 책)을 꺼내려면, 위에 있는 책을 먼저 다 치워야 한다.
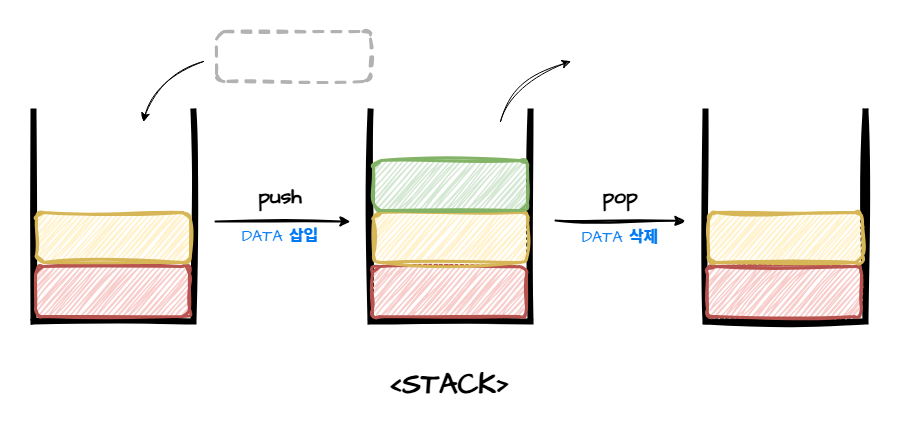
🔸스택의 연산
| 연산 | 설명 | 시간 복잡도 |
| push | 스택에 새로운 데이터 삽입 | O(1) |
| pop | 스택에서 가장 위에 있는 데이터 삭제 | O(1) |
| peek | 스택에서 가장 위에 있는 데이터 확인 | O(1) |
| isEmpty | 스택이 비어 있는지 확인 | O(1) |
| isFull | 스택이 가득 찼는지 확인 | O(1) |
🔸스택이 사용되는 곳
- 브라우저 히스토리 (뒤로가기/앞으로 가기)
- 프로그램의 함수 호출 : 함수가 호출되면 현재 함수의 실행 정보가 스택에 쌓이고, 실행이 완료되면 스택에서 제거되어 이전 함수로 돌아감 (ex: 재귀 호출)
📌큐
🔸큐의 특징
- 선입선출(FIFO) 구조 - 먼저 들어간 게 먼저 나옴
- 데이터를 추가하는 곳(Rear)과 제거하는 곳(Front)이 다름
- 새로운 데이터가 계속 들어오면, 아직 사용하지 않은 데이터도 유지해야 함
- 이미 사용한 데이터도 남아있는 경우가 많아 메모리 사용량이 많아짐

🔸큐의 연산
| 연산 | 설명 | 시간 복잡도 |
| enqueue | 큐의 rear에 새로운 데이터 삽입 | O(1) |
| dequeue | 큐의 front에서 데이터 삭제 | O(1) |
| peek | 큐의 front에 있는 데이터 확인 | O(1) |
| isEmpty | 큐가 비어 있는지 확인 | O(1) |
| isFull | 큐가 가득 찼는지 확인 | O(1) |
🔸큐가 사용되는 곳
- 프린터 대기열
- CPU 작업 스케줄링
- 메시지 큐
- 이벤트 처리 시스템
💡큐의 메모리 사용에 대하여
- 큐는 데이터가 삭제되어도 메모리 공간이 그대로 남아있다. 하지만 기본적인 큐에서는 앞쪽이 비어도 뒤쪽에서만 계속 데이터를 추가하다 보니 메모리 낭비가 발생할 수 있다.
카페에서 줄을 서서 주문을 한다고 가정해보자.
큐는 FIFO이므로 먼저 줄을 선 사람이 먼저 주문을 하고 나가고, 새로운 사람이 줄 끝에서 대기해야 한다.
A, B, C가 차례로 줄을 서 있다고 가정할 때, A가 떠났다고 해서 줄의 공간이 자동으로 앞당겨지는 것은 아니다.
A가 떠났지만, A가 서 있던 공간이 남아있고 그 뒤에 B, C가 서 있는 것이다.
큐는 앞에서 데이터가 빠져도 남은 데이터들이 자동으로 앞당겨지지 않으므로 데이터가 빠진 공간이 재활용되지 않아 메모리 낭비가 발생한다.
(순환 큐를 이용하면 재활용이 가능하긴 하다.)

끝까지 읽어주셔서 감사합니다 :)
Have a good day🐱
1. 개발자 준비생이 공부한 내용을 정리한 글입니다. 내용에 오류가 있을 수 있습니다.
2. 위와 같은 이유로 내용에 대한 지적과 조언은 감사하게 받습니다.
3. 이 글의 내용은 계속 공부함으로써 언제든지 추가/수정 될 수 있습니다.
'Coding Test > Algorithm' 카테고리의 다른 글
| JAVA 입/출력 성능 비교 (Scanner vs BufferedReader vs System.in.read()) (1) | 2026.01.11 |
|---|---|
| 시간 복잡도(Time Complexity) feat. 빅오 표기법 (0) | 2025.01.07 |
| JAVA) System.in.read()로 정수 입력받기 (0) | 2024.12.28 |